A quick guide to getting data using JavaScript.
Tweet
In this article I would like to show one of the most basic ways to scrap data from a website. What this method lacks in elegance, it makes up for in efficiency. What we do is the following:
- Go to the website we want to scrap
- Use Google’s inspector and console to analyze the site
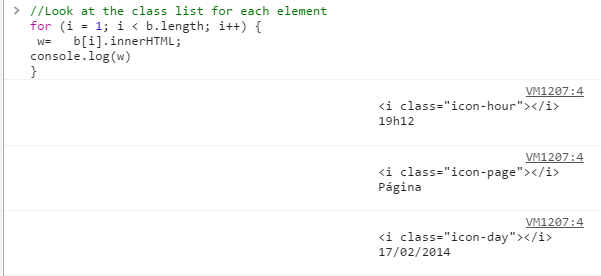
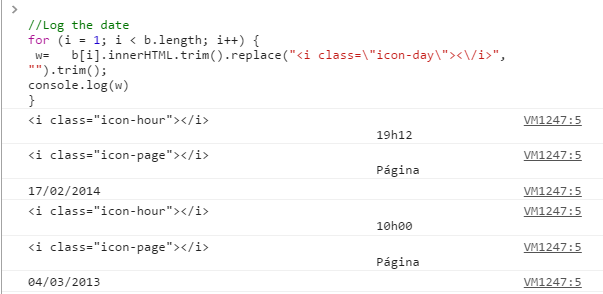
- Run a JavaScript function to get the data
- Save the data into a text file
Context
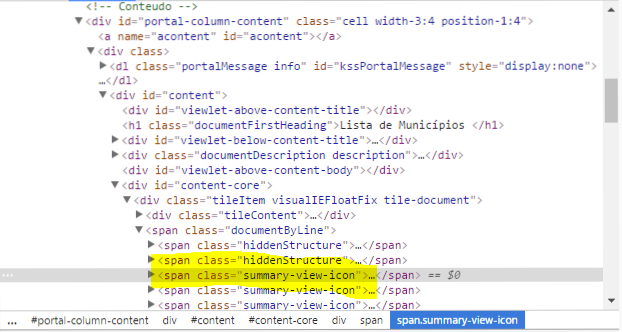
Brazil has an anticorruption program that audits local governments every month. The local governments are selected randomly through a monthly national contest. The goal of this project is to get metadata on each contest. In particular, we are interested in getting the contest number and date. The contest data is available on this site.To get the data, we first need to look at Google Inspect to understand how the data is stored.

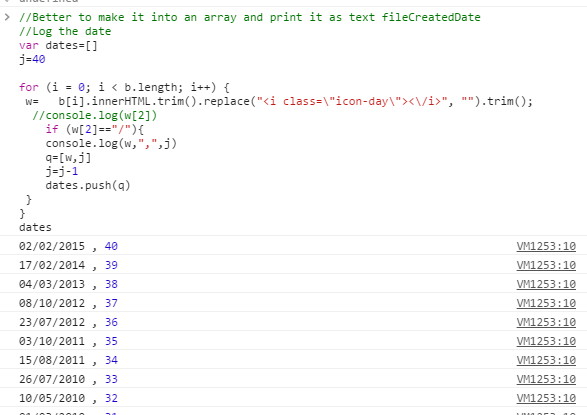

Disclaimer: Note that this procedure is meant for a rough data gathering or as a proof of concept.